TimeWak: Temporal Chained-Hashing Watermark for Time Series Data
Zhi Wen Soi, Chaoyi Zhu, Fouad Abiad, Aditya Shankar, Jeroen Galjaard, Huijuan Wang, Lydia Y. Chen
NeurIPS 2025 (🏆 Spotlight): 📄 Paper | 💻 Code
Citation
@inproceedings{soi2025timewak,
author = {Zhi Wen Soi and
Chaoyi Zhu and
Fouad Abiad and
Aditya Shankar and
Jeroen M. Galjaard and
Huijuan Wang and
Lydia Y. Chen},
title = {TimeWak: Temporal Chained-Hashing Watermark for Time Series Data},
year = {2025}
}
Collaborative and Confidential Junction Trees for Hybrid Bayesian Networks
Roberto Gheda, Abele Mălan, Thiago Guzella, Carlo Lancia, Robert Birke, Lydia Y. Chen
NeurIPS 2025: 💻 Code
Citation
@inproceedings{gheda2025ccjt,
author = {Roberto Gheda and
Abele Mălan and
Thiago Guzella and
Carlo Lancia and
Robert Birke and
Lydia Y. Chen},
title = {Collaborative and Confidential Junction Trees for Hybrid Bayesian Networks},
year = {2025}
}
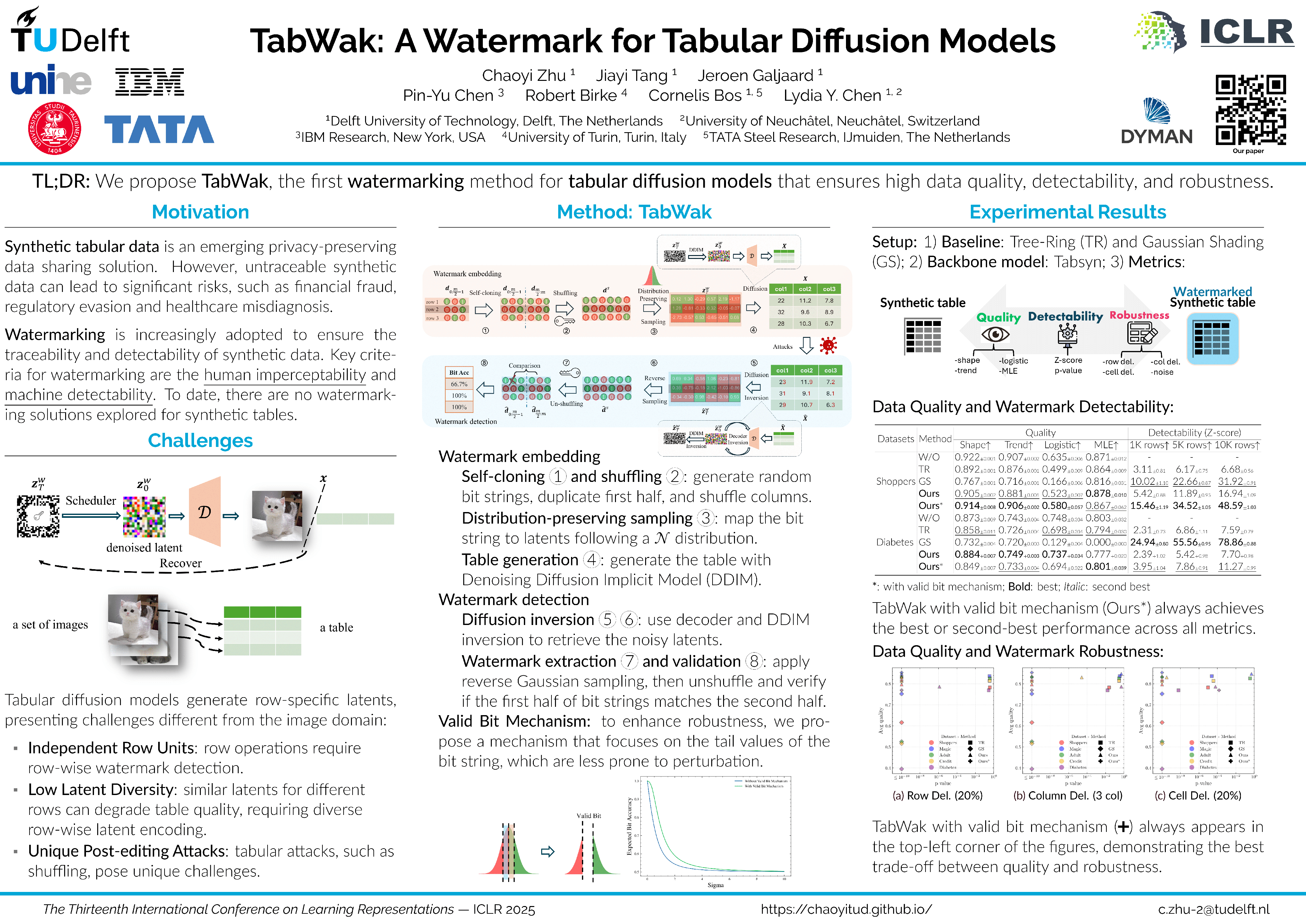
TabWak: A Watermark for Tabular Diffusion Models
Chaoyi Zhu, Jeroen Galjaard, Pin-Yu Chen, Lydia Y. Chen
ICLR 2025 (🏆 Spotlight): 📄 Paper | 💻 Code | 🖼️ Poster
{kind=link}
Citation
@inproceedings{zhu2025tabwak,
author = {Chaoyi Zhu and
Jiayi Tang and
Jeroen M. Galjaard and
Pin{-}Yu Chen and
Robert Birke and
Cornelis Bos and
Lydia Y. Chen},
title = {TabWak: A Watermark for Tabular Diffusion Models},
booktitle = {The Thirteenth International Conference on Learning Representations, {ICLR} 2025},
publisher = {OpenReview.net},
year = {2025}
}
Duwak: Dual Watermarks in Large Language Models
Chaoyi Zhu, Jeroen Galjaard, Pin-Yu Chen, Lydia Y. Chen
ACL 2024: 📄 Paper | 💻 Code
Citation
@inproceedings{zhu2024duwak,
author = {Chaoyi Zhu and
Jeroen M. Galjaard and
Pin{-}Yu Chen and
Lydia Y. Chen},
title = {Duwak: Dual Watermarks in Large Language Models},
booktitle = {Findings of the Association for Computational Linguistics: ACL 2024},
publisher = {Association for Computational Linguistics},
year = {2024},
doi = {10.18653/v1/2024.findings-acl.678}
}
WaveStitch: Flexible and Fast Conditional Time Series Generation with Diffusion Models
Aditya Shankar, Lydia Y. Chen, Arie van Deursen and Rihan Hai
SIGMOD 2026: 📄 Paper | 💻 Code
Citation
@article{shankar2025wavestitch,
author = {Aditya Shankar and
Lydia Y. Chen and
Arie van Deursen and
Rihan Hai},
title = {WaveStitch: Flexible and Fast Conditional Time Series Generation with Diffusion Models},
journal = {CoRR},
volume = {abs/2503.06231},
year = {2025}
}
Detective SAM: Adapting SAM to Localize Diffusion-based Forgeries via Embedding Artifacts
Gert Lek, Chaoyi Zhu, Pin-Yu Chen, Robert Birke, Lydia Y. Chen
ICML 25 Workshop: 📄 Paper
Citation
@inproceedings{lek2025detectivesam,
author = {Gert Lek and
Chaoyi Zhu and
Pin-Yu Chen and
Robert Birke and
Lydia Y. Chen},
title = {Detective SAM: Adapting SAM to Localize Diffusion-based Forgeries via Embedding Artifacts},
booktitle = {ICML Workshops},
pages = {1--12},
year = {2025}
}
Match & Choose: Model Selection Framework for Fine-tuning Text-to-Image Diffusion Models
Basile Lewandowski, Robert Birke, Lydia Y. Chen
📄 Paper
Citation
@inproceedings{lewandowski2025mc,
author = {Basile Lewandowski and
Robert Birke and
Lydia Y. Chen},
title = {Match & Choose: Model Selection Framework for Fine-tuning Text-to-Image Diffusion Models},
journal = {CoRR},
volume = {abs/2508.10993},
year = {2025}
}
CCBNet: Confidential Collaborative Bayesian Networks Inference
Abele Mălan, Thiago Guzella, Jérémie Decouchant, Lydia Y. Chen
FC 2025: 📄 Paper | 💻 Code
Citation
@inproceedings{malan2025ccbnet,
author = {Abele Mălan and
Thiago Guzella and
Jérémie Decouchant and
Lydia Y. Chen},
title = {CCBNet: Confidential Collaborative Bayesian Networks Inference},
booktitle = {Financial Cryptography and Data Security - 29th International Conference, {FC} 2025},
series = {Lecture Notes in Computer Science},
publisher = {Springer},
year = {2025}
}
TS-Inverse: A Gradient Inversion Attack Tailored for Federated Time Series Forecasting Models
Caspar Meijer, Jiyue Huang, Shreshtha Sharma, Elena Lazovik, Lydia Y. Chen
SaTML 2025: 📄 Paper | 💻 Code
Citation
@inproceedings{meijer2025tsinverse,
author = {Caspar Meijer and
Jiyue Huang and
Shreshtha Sharma and
Elena Lazovik and
Lydia Y. Chen},
title = {TS-Inverse: {A} Gradient Inversion Attack Tailored for Federated Time Series Forecasting Models},
booktitle = {IEEE Conference on Secure and Trustworthy Machine Learning, SaTML 2025},
publisher = {IEEE},
year = {2025},
doi = {10.1109/SATML64287.2025.00014}
}
BatMan-CLR: Making Few-shots Meta-Learners Resilient Against Label Noise
Jeroen Galjaard, Robert Birke, Juan Pérez, and Lydia Y. chen
ECML 2025: 📄 Paper | 💻 Code
Citation
@inproceedings{galjaard2025batmanclr,
author = {Jeroen Galjaard and
Robert Birke and
Juan Perez and
Lydia Y. Chen},
title = {BatMan-CLR: Making Few-shots Meta-Learners Resilient Against Label Noise.},
booktitle = {Machine Learning and Knowledge Discovery in Databases. Research Track - European Conference, {ECML} {PKDD} 2025},
year = {2025}
}
Federated Time Series Generation on Feature and Temporally Misaligned Data
Zhi Wen Soi, Chenrui Fan, Aditya Shankar, Abele Mălan, Lydia Y. Chen
ECML 2025: 📄 Paper | 💻 Code
Citation
@inproceedings{soi2025fedtdd,
author = {Zhi Wen Soi and
Chenrui Fan and
Aditya Shankar and
Abele Mălan and
Lydia Y. Chen},
title = {Federated Time Series Generation on Feature and Temporally Misaligned Data},
booktitle = {Machine Learning and Knowledge Discovery in Databases. Research Track - European Conference, {ECML} {PKDD} 2025},
year = {2025}
}
TabuLa: Harnessing Language Models for Tabular Data Synthesis
Zilong Zhao, Robert Birke, Lydia Y. Chen
PAKDD 2025: 📄 Paper | 💻 Code
Citation
@inproceedings{zhao2025stv,
author = {Zilong Zhao and
Robert Birke and
Lydia Y. Chen},
title = {TabuLa: Harnessing Language Models for Tabular Data Synthesis},
booktitle = {Advances in Knowledge Discovery and Data Mining - 29th Pacific-Asia Conference on Knowledge Discovery and Data Mining, {PAKDD} 2025},
series = {Lecture Notes in Computer Science},
publisher = {Springer},
year = {2025},
doi = {10.1007/978-981-96-8186-0\_20}
}
Share Secrets for Privacy: Confidential Forecasting with Vertical Federated Learning
Aditya Shankar, Jérémie Decouchant Decouchant, Dimitra Gkorou, Rihan Hai, Lydia Y. Chen
ARES 2025: 📄 Paper | 💻 Code
Citation
@inproceedings{shankar2025stv,
author = {Aditya Shankar and
Jérémie Decouchant and
Dimitra Gkorou and
Rihan Hai and
Lydia Y. Chen},
title = {Share Secrets for Privacy: Confidential Forecasting with Vertical Federated Learning},
booktitle = {Proceedings of the 19th International Conference on Availability, Reliability and Security, {ARES} 2025},
publisher = ,
year = {2025}
}
SkipPipe: Partial and Reordered Pipelining Framework for Training LLMs in Heterogeneous Networks
Nikolay Blagoev, Lydia Y. Chen, Oğuzhan Ersoy
📄 Paper | 💻 Code
Citation
@inproceedings{blagoev2025skippipe,
author = {Nikolay Blagoev and
Lydia Yiyu Chen and
Oguzhan Ersoy},
title = {SkipPipe: Partial and Reordered Pipelining Framework for Training LLMs in Heterogeneous Networks},
journal = {CoRR},
volume = {abs/2502.19913},
year = {2025}
}
LeadFL: Client Self-Defense against Model Poisoning in Federated Learning
Chaoyi Zhu, Stefanie Roos, Lydia Y. Chen
ICML 2023: 📄 Paper | 💻 Code | 🖼️ Poster
{kind=link}
Citation
@inproceedings{zhu2023leadfl,
author = {Chaoyi Zhu and
Stefanie Roos and
Lydia Y. Chen},
title = {LeadFL: Client Self-Defense against Model Poisoning in Federated Learning},
booktitle = {International Conference on Machine Learning, {ICML} 2023},
series = {Proceedings of Machine Learning Research},
publisher = ,
year = {2023}
}
Gradient Inversion of Federated Diffusion Models
Jiyue Huang, Chi Hong, Stefanie Roos and Lydia Y. Chen
ARES 2025: 📄 Paper | 💻 Code
Citation
@inproceedings{huang2025gidm,
author = {Jiyue Huang and
Chi Hong and
Stefanie Ross and
Lydia Y. Chen},
title = {Gradient Inversion of Federated Diffusion Models},
booktitle = {Proceedings of the 19th International Conference on Availability, Reliability and Security, {ARES} 2025},
publisher = ,
year = {2025}
}
On Quantifying the Gradient Inversion Risk of Data Reuse in Federated Learning Systems
Jiyue Huang, Lydia Y. Chen, Stefanie Roos
SRDS 2024: 📄 Paper | 💻 Code
Citation
@inproceedings{huang2024cgi,
author = {Jiyue Huang and
Lydia Y. Chen and
Stefanie Roos},
title = {On Quantifying the Gradient Inversion Risk of Data Reuse in Federated Learning Systems},
booktitle = {43rd International Symposium on Reliable Distributed Systems, {SRDS} 2024},
publisher = {IEEE},
year = {2024},
doi = {10.1109/SRDS64841.2024.00031}
}
Fabricated Flips: Poisoning Federated Learning without Data
Jiyue Huang, Zilong Zhao, Lydia Y. Chen, Stefanie Roos
DSN 2023: 📄 Paper | 💻 Code
Citation
@inproceedings{huang2024dfa,
author = {Jiyue Huang and
Zilong Zhao and
Lydia Y. Chen and
Stefanie Roos},
title = {Fabricated Flips: Poisoning Federated Learning without Data},
booktitle = {53rd Annual {IEEE/IFIP} International Conference on Dependable Systems and Network, {DSN} 2023},
publisher = ,
year = {2023},
doi = {10.1109/DSN58367.2023.00036}
}
CTAB-GAN: Effective Table Data Synthesizing
Zilong Zhao, Aditya Kunar, Hiek Van der Scheer, Robert Birke, Lydia Y. Chen
ACML 2021: 📄 Paper | 💻 Code
Citation
@inproceedings{zhao2021ctabgan,
author = {Zilong Zhao and
Aditya Kunar and
Robert Birke and
Lydia Y. Chen},
title = {CTAB-GAN: Effective Table Data Synthesizing},
booktitle = {Asian Conference on Machine Learning, {ACML} 2021},
series = {Proceedings of Machine Learning Research},
publisher = ,
year = {2021}
}